Product documentation
In this topic the basic setup for Data Masking will be explained. In the Data Masking app, the area Settings is available. Via this menu it is possible to access the different setup entities that are part of the Data Masking solution.
In the next paragraphs the Settings entities are described.
Data Masking > Settings > General Settings
The parameters of Data Masking are explained here.
Data Masking > Settings > Configuration
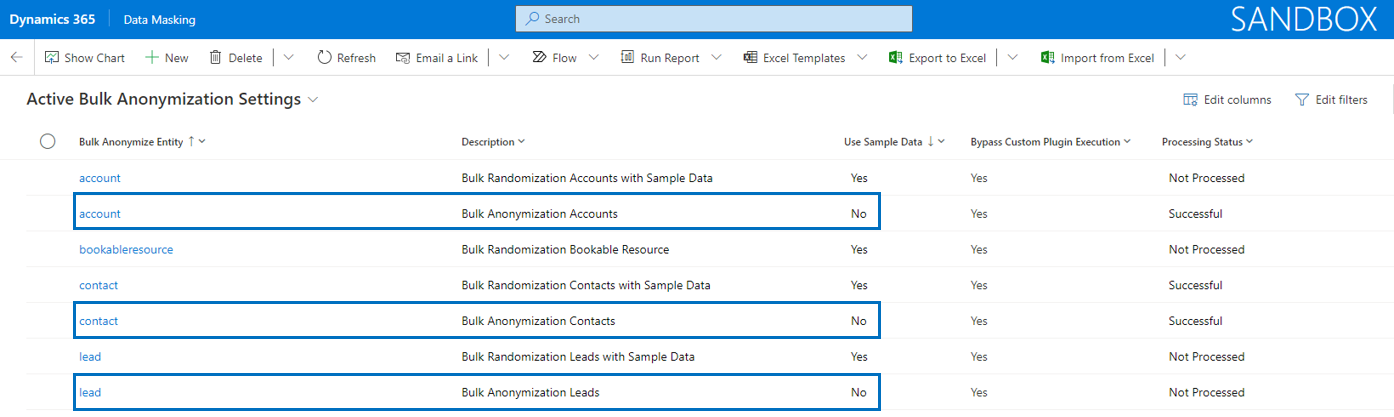
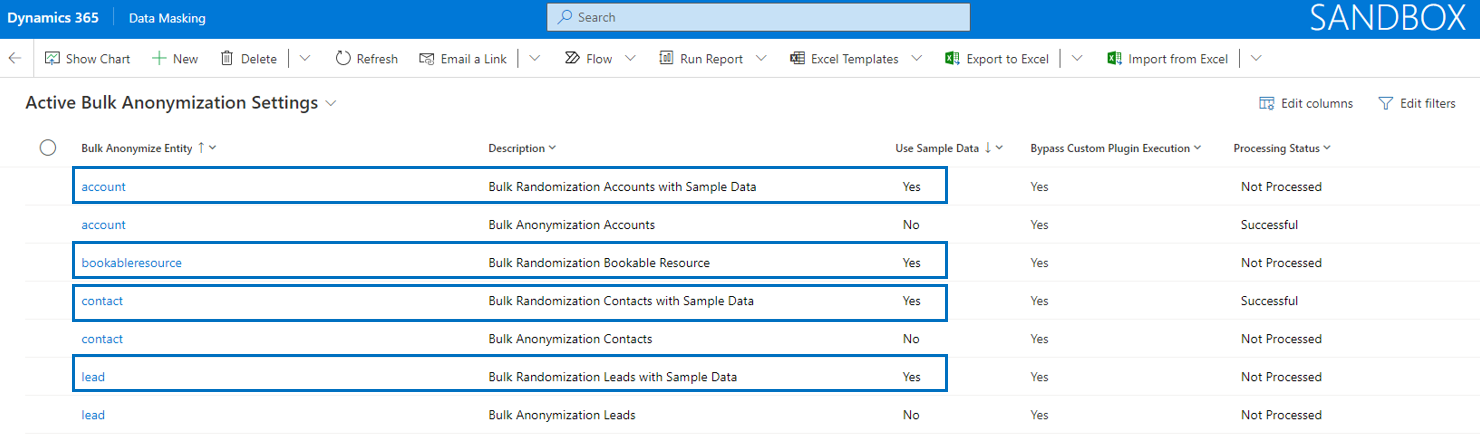
The entity Bulk Anonymization Settings needs to be defined as a prerequisite for being able to anonymize records in bulk for a specific entity. Via the Setting Values each field that requires anonymization can be setup in a specific format that is used when records are being anonymized. Bulk anonymization leads to processed records that are not recognizable and hardly readable.
Bulk anonymization processes records to an unreadable format of text fields using a fixed value or random values. Further, other attribute types like for example date/time, two options or an option set can be set to a specific value, depending on the attribute type.
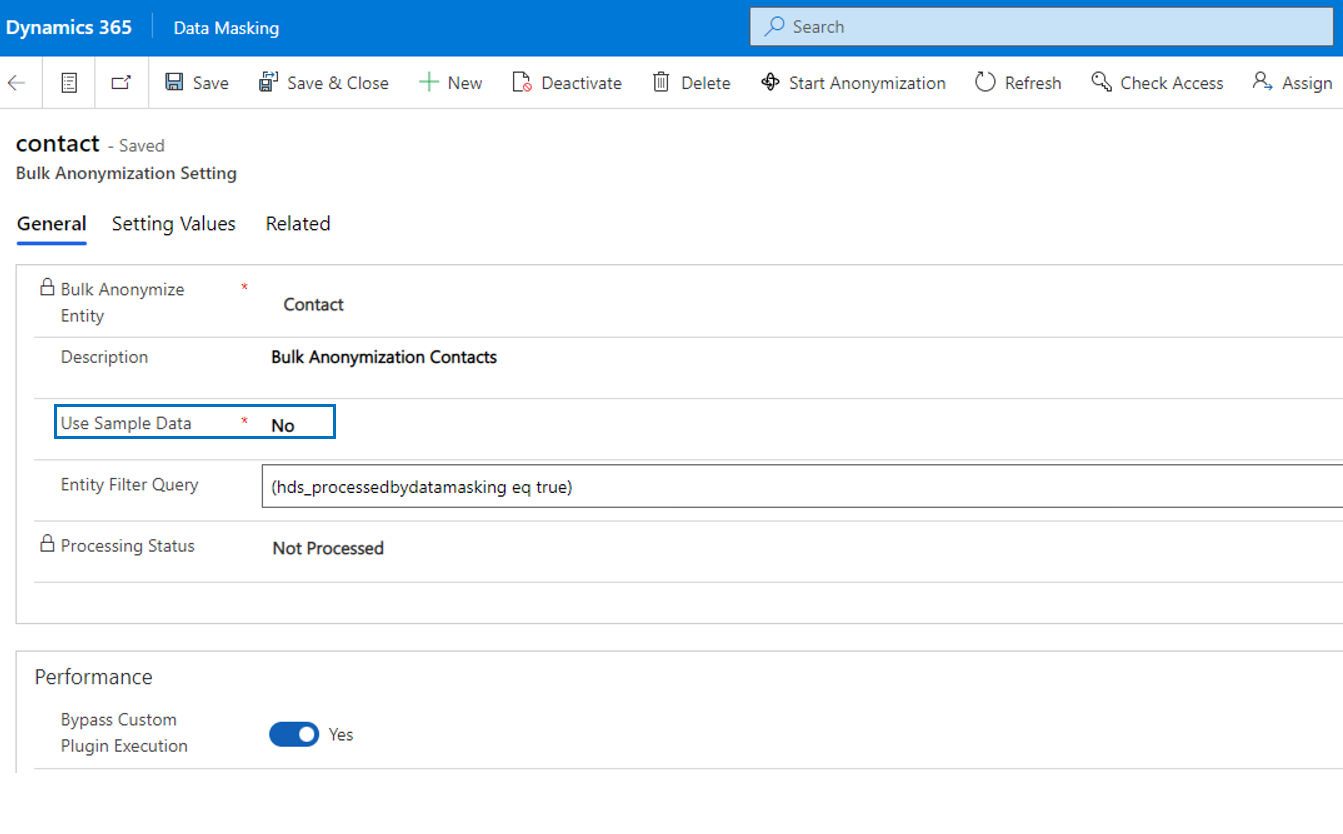
If the field Use Sample Data is set to No, it has the consequence that sample data can not be used, which will lead to complete anonymization of the records for that specific entity.
| Field | Description |
| Bulk Anonymize Entity | The entity that requires bulk anonymization. |
| Description | Description of the bulk anonymization setting record. |
| Use Sample Data | If Use Sample Data is set to No, then it is not possible to select sample data for text fields. It will lead to full anonymization of records resulting in not recognizable and hardly readable data. |
| Entity Filter Query | This field is optional and can be used to define a filter for selecting records that will be processed. If for example you have masked a large number of contacts and you need to process records that are unprocessed, you can set this query as following (hds_processedbydatamasking eq false). Technically this is an OData filter. You can build a filter via FetchXml Builder in the XrmToolbox. |
| Processing Status | The field Processing Status is set automatically and has the values Not Processed, In Progress, Successful and Failed. |
| Bypass Custom Plugin Execution | If field Bypass Custom Plugin Execution is set to Yes, the performance of processing records will improve as any custom code for that specific entity will be skipped during the update. |
Note that it is only allowed to define two unique records per entity: one with Use Sample Data set to No (anonymization) and one with Use Sample Data set to Yes (randomization).

It is possible to create bulk anonymization settings for any (custom) entity.
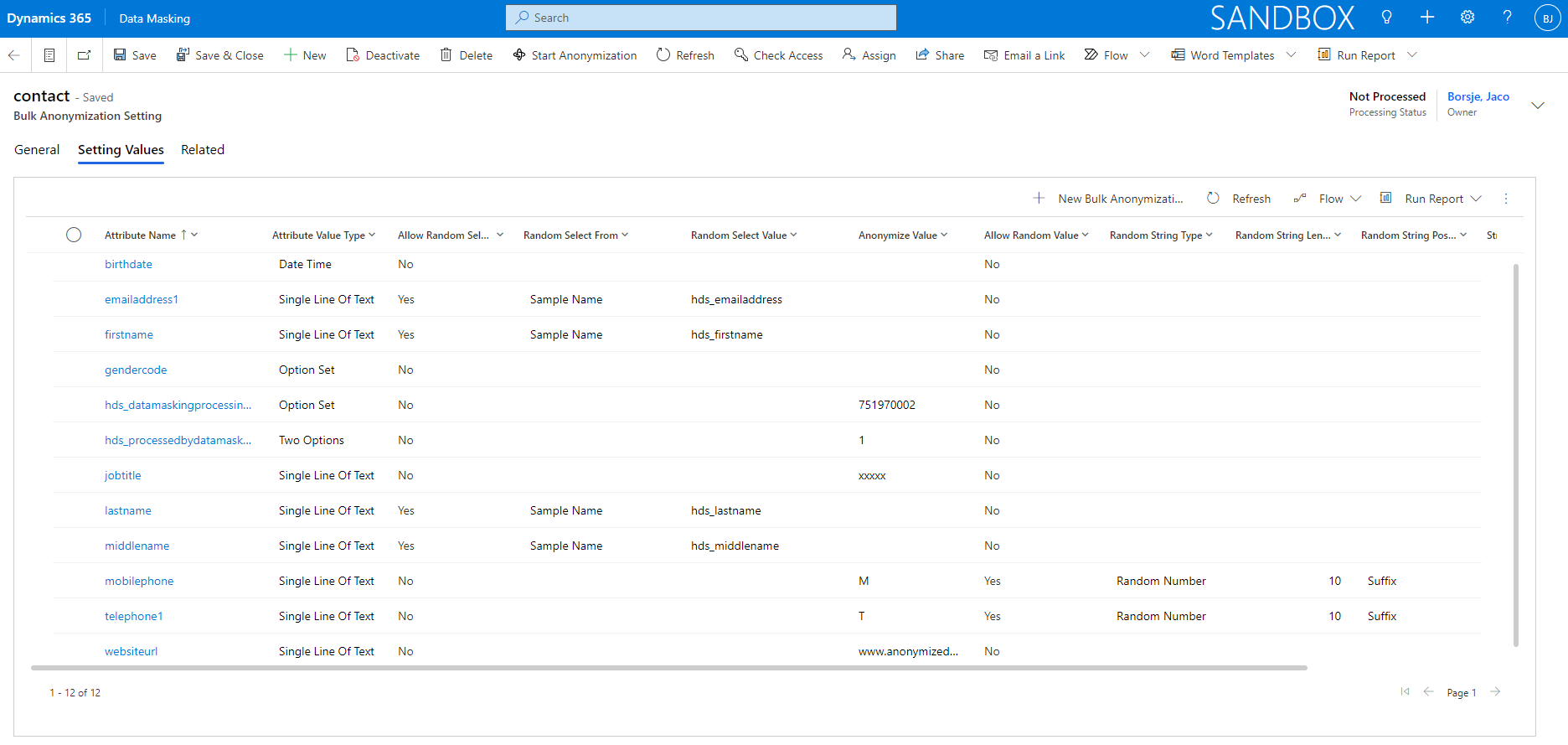
When an entity has been defined in bulk anonymization settings, it is necessary to define the Setting Values of the entity in order to be able to process the bulk anonymization. Via the Setting Values each field that requires anonymization can be setup in a specific format that is used when a record is being anonymized.
Note that the setting values (fields) of the entity forms are automatically added when an anonymization setting record is created (except lookups and fields like created on, created by, modified on, modified by and ownerid).
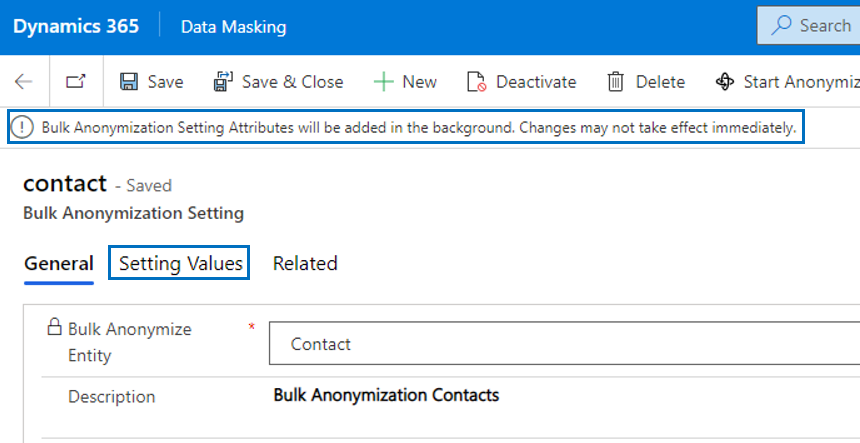
Important
For each setting value the fields Attribute Name and Attribute Value Type must be defined. The field Anonymize Value is mandatory when attribute type Two Option, Status or Status Reason is selected. Once defined, the record definitions will be used by the anonymization cloud flow. Note that it is also possible to 'clear' a value of a field by leaving the field Anonymize Value as <blank>.
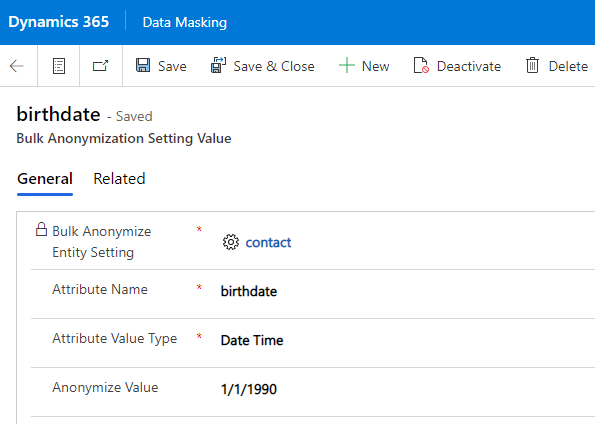
When defining a field with attribute value type Option Set, it is required to use the exact technical value as defined in the Option Set and fill that value in the field Anonymize Value.
Important
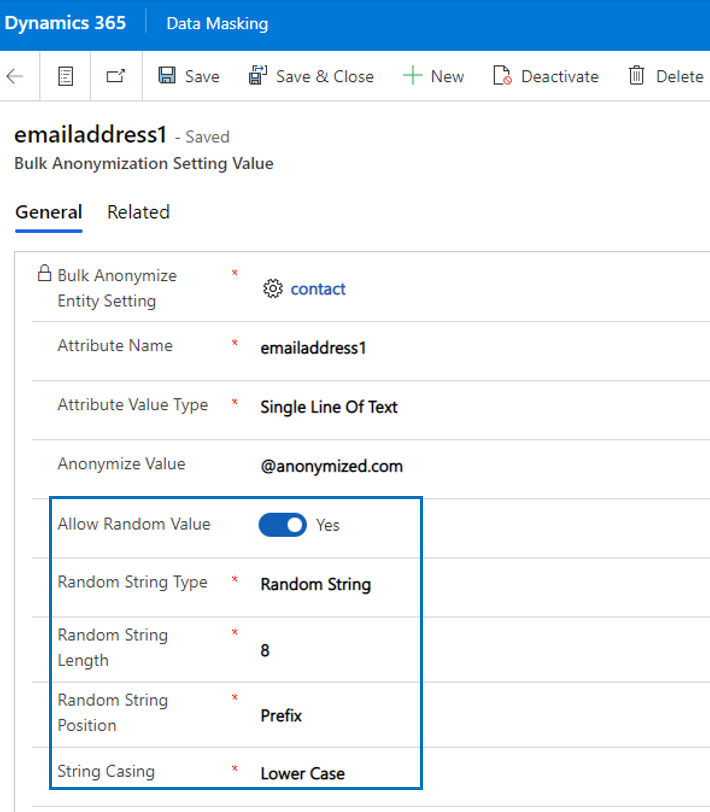
Last but not least, for attribute value types Single Line Of Text and Multiple Lines Of Text it is possible to set the value Allow Random Value to Yes. When selecting that option, additional fields will be visible and become business required. The effect of these settings is that the field is anonymized in a random way, depending on the selected values for random anonymization.
| Field | Description |
| Attribute Name |
The logical name of the field that needs to be anonymized. |
| Attribute Value Type |
The following type of fields are supported for anonymization: Currency, Date Time, Decimal Number, Multiple Lines Of Text, Option Set, Single Line Of Text, Status, Status Reason, Two Options and Whole Number. |
| Anonymize Value | Anonymize value which is depending on the attribute value type field. |
| Allow Random Value | Is a random value allowed (only available for Single Line Of Text and Multiple Lines Of Text)? |
| Random String Type | Values: Random String, Random Number and Random Mix (a combination of both string and number). |
| Random String Length | Define the random string length which should be a number between 4 and 12. |
| Random String Position | Values: Prefix or Suffix |
| String Casing | Values: Upper Case, Lower Case & Proper Case. This field is not visible if type Random Number is selected. |
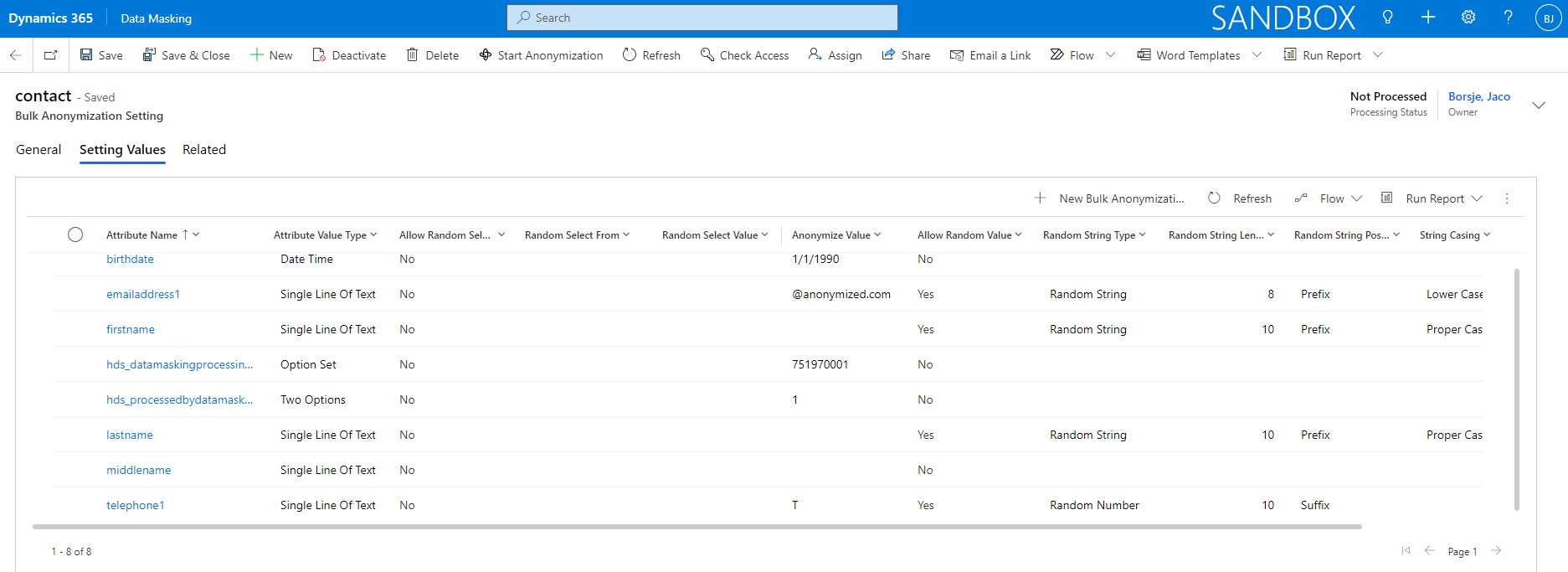
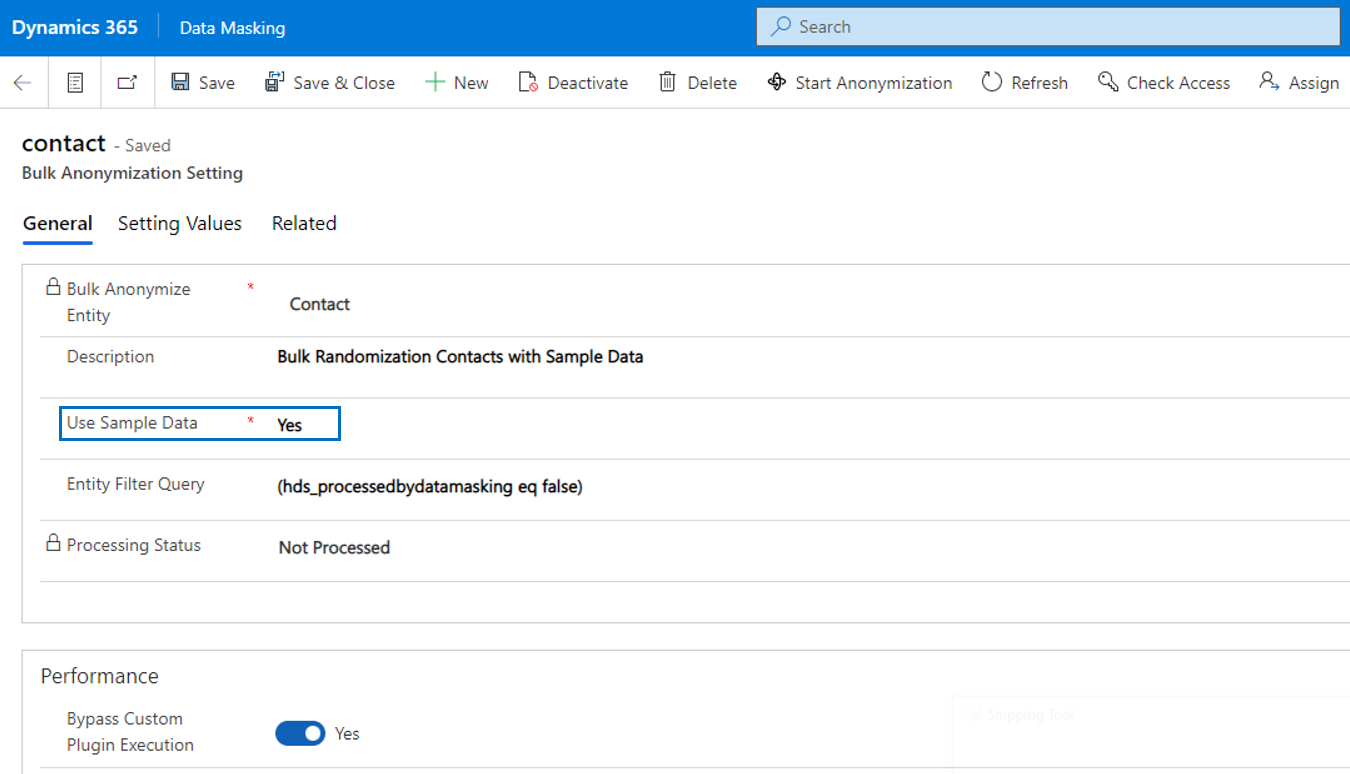
The entity Bulk Anonymization Settings needs to be defined as a prerequisite for being able to randomize records in bulk for a specific entity. For randomization, the field Use Sample Data must be set to Yes. In that case attribute types Single Line Of Text and Multiple Lines Of Text can be mapped to sample data (names and addresses) which will lead to randomization of the records for that specific entity.
Via the Setting Values each field that requires randomization can be setup in a specific format that is used when records are being randomized. Data Masking contains two specific entities for sample names and addresses. Mapping entity fields to these sample name and sample address fields will lead to processed records still showing readable, but fake random data.
Bulk randomization processes records to readable format of text fields using sample data. Further, other attribute types like for example date/time, two options or an option set can be set to a specific value, depending on the attribute type.
| Field | Description |
| Bulk Anonymize Entity | The entity that requires bulk anonymization. |
| Description | Description of the bulk anonymization setting record. |
| Use Sample Data | If Use Sample Data is set to Yes, then it is possible to select sample data for text fields. It will lead to randomization of records resulting in readable but fake data. |
| Entity Filter Query | This field is optional and can be used to define a filter for selecting records that will be processed. If for example you have masked a large number of contacts and you need to process records that are unprocessed, you can set this query as following (hds_processedbydatamasking eq false). Technically this is an OData filter. You can build a filter via FetchXml Builder in the XrmToolbox. |
| Processing Status | The field Processing Status is set automatically and has the values Not Processed, In Progress, Successful and Failed. |
| Bypass Custom Plugin Execution | If field Bypass Custom Plugin Execution is set to Yes, the performance of processing records will improve as any custom code for that specific entity will be skipped during the update. |
Note that it is only allowed to define two unique records per entity: one with Use Sample Data set to No (anonymization) and one with Use Sample Data set to Yes (randomization).
It is possible to create bulk randomization settings for any (custom) entity.
When an entity has been defined in bulk anonymization settings and Use Sample Data is Yes, it is necessary to define the Setting Values of the entity in order to be able to process the bulk randomization. Via the Setting Values each field that requires randomization can be setup in a specific format that is used when a record is being randomized.
Note that the setting values (fields) of the entity forms are automatically added when an randomization setting record is created (except lookups and fields like created on, created by, modified on, modified by and ownerid).
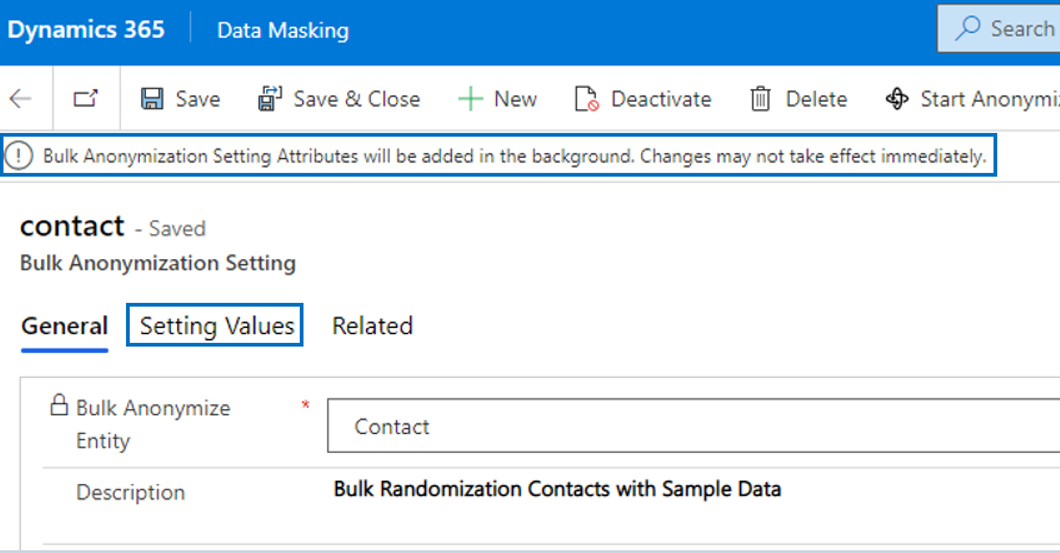
Important
For each setting value the fields Attribute Name and Attribute Value Type must be defined. The field Anonymize Value is mandatory when attribute type Two Option, Status or Status Reason is selected. Once defined, the record definitions will be used by the randomization cloud flow. Note that it is also possible to 'clear' a value of a field by leaving the field Anonymize Value as <blank>.
When defining a field with attribute value type Option Set, it is required to use the exact technical value as defined in the Option Set and fill that value in the field Anonymize Value.
Important
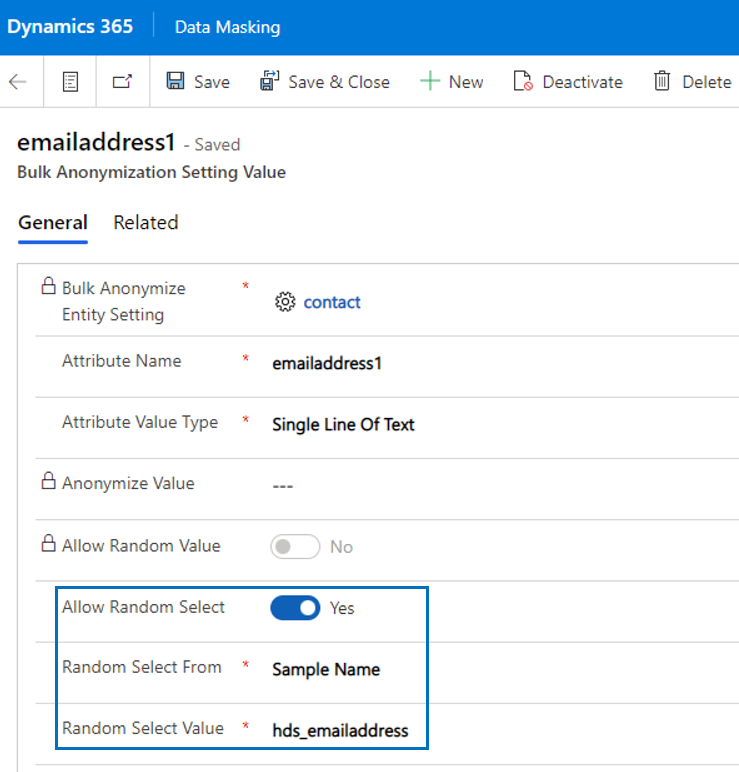
Last but not least, for attribute value types Single Line Of Text and Multiple Lines Of Text it is possible to set the value Allow Random Select to Yes. When selecting that option, additional fields will be visible and become business required. Text fields can than be mapped to either sample name fields or sample address fields. The effect of these settings is that the field is processed in a random way, depending on the selected values for randomization. When Allow Random Select is Yes, the fields Anonymize Value is cleared, Allow Random Value is set No and both fields will be locked.
Note that it is also possible to set text fields to value Allow Random Value to Yes. When selecting that option, different fields will be visible and become business required. The working of Allow Random Value is described in paragraph Bulk Anonymization Setting Values.
| Field | Description |
| Attribute Name |
The logical name of the field that needs to be randomized. |
| Attribute Value Type |
The following type of fields are supported for randomization: Currency, Date Time, Decimal Number, Multiple Lines Of Text, Option Set, Single Line Of Text, Status, Status Reason, Two Options and Whole Number. |
| Anonymize Value | Anonymize value which is depending on the attribute value type field but cleared and locked if the Allow Random Select is set to Yes. |
| Allow Random Value | Is a random value allowed (only available for Single Line Of Text and Multiple Lines Of Text)? The field is locked if the Allow Random Select is set to Yes. |
| Allow Random Select | Will sample data be used to randomize this field (only available for Single Line Of Text and Multiple Lines Of Text)? The field is locked if the Allow Random Value is set to Yes. |
| Random Select From | Is the value randomly selected from entity Sample Name or entity Sample Address? |
| Random Select Value | What is the logical name of the mapped field either from entity Sample Name or entity Sample Address? |
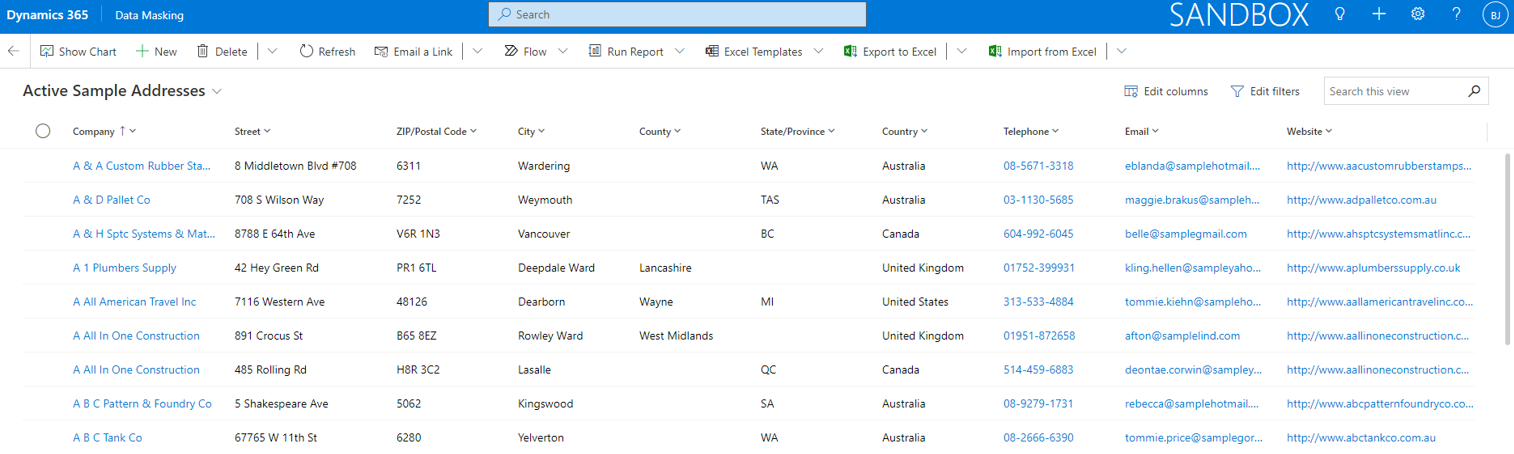
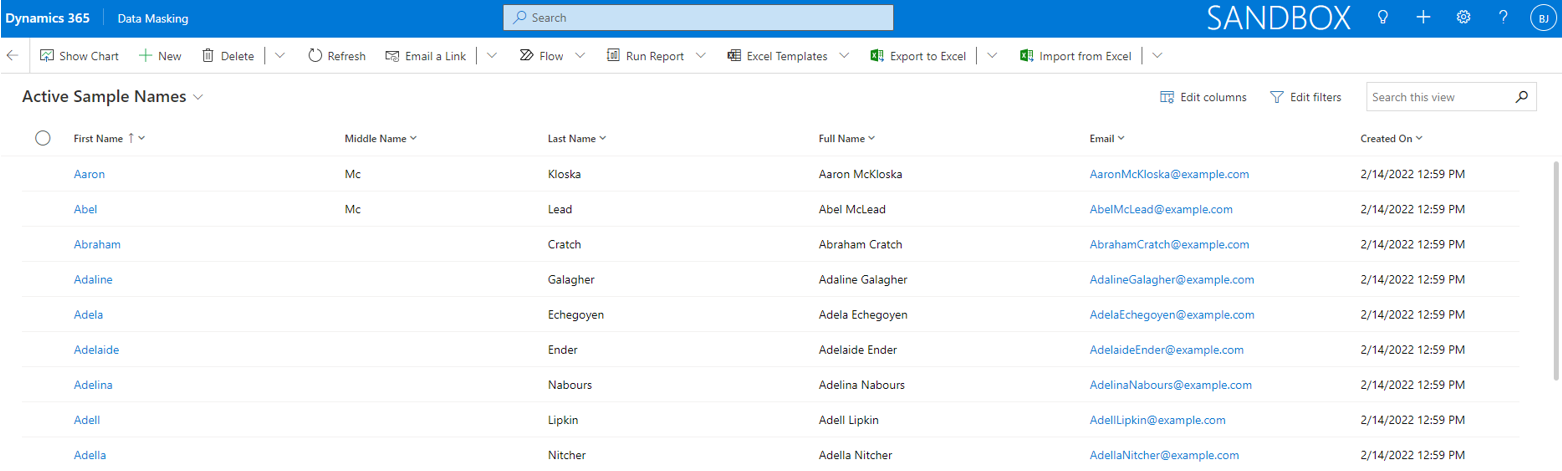
Data Masking > Sample Data
The entity Sample Names is used to upload sample name records. The record fields from this entity are randomly used for text fields (if mapped) in the randomization process.
Note that during initial installation of Data Masking, 2000 sample names will be imported in this entity. If you like to use your own sample data, the existing records can be easily deleted via a bulk record deletion system job.
The entity Sample Addresses is used to upload sample address records. The record fields from this entity are randomly used for text fields (if mapped) in the randomization process.
Note that during initial installation of Data Masking, 2000 sample addresses will be imported in this entity. If you like to use your own sample data, the existing records can be easily deleted via a bulk record deletion system job.